1. Introduction
Amazon SageMaker 는 기계학습 모델을 빠르고 쉽게 구축 및 훈련시킬 수 있는 도구로, 훈련된 모델을 프로덕션 환경까지 직접 배포할 수 있습니다. 데이터 원본에 접근 및 분석을 위해 내장형 Jupyter notebook 인스턴스를 제공하기 때문에 별도의 서버를 관리할 필요가 없습니다. 또한 분산된 환경 내 대규모 데이터를 효율적으로 실행하는 데 최적화된 일반 기계 학습 알고리즘 또한 제공합니다. 특히 SageMaker Pipelines 는 직접 Amazon SageMaker 를 통합하고 워크플로를 관리할 수 있기 때문에 기계학습 Pipeline 을 구축할 수 있는 도구 입니다. 이러한 워크플로 구성 요소를 사용하면 프로덕션 환경에서 수백 개의 모델을 구축, 교육, 테스트 및 배포하는 능력을 쉽게 확장하고, 더 빠르게 반복하고, 수동 오케스트레이션으로 인한 오류를 줄이고, 반복 가능한 메커니즘을 구축할 수 있습니다.
이 게시물에서는 imtrial 에서 AI서비스를 구축하기 위한 Amazon SageMaker 를 활용한 NLP Pipeline 구성을 설명 합니다.
2. Configuration
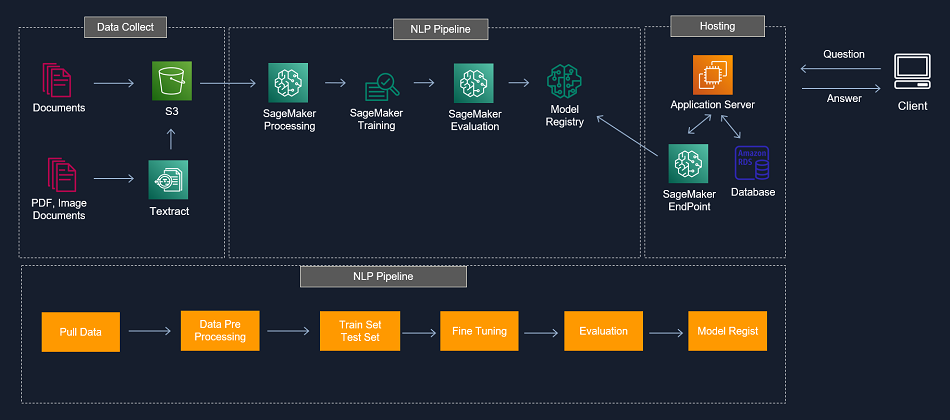
imtrial 의 AI 서비스를 구축하기 위한 구성은 크게 데이터 수집 영역, 기계학습 Pipeline 영역, 사용자에게 서비스를 제공하는 호스팅 영역으로 구분할 수 있습니다.
2.1. Data Collect
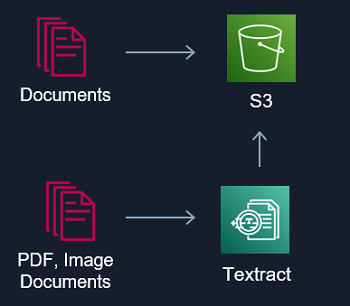
imtrial 에서는 NLP 를 활용한 AI 서비스에 많은 임상시험 규정 및 프로토콜 등 문서를 활용하고 있습니다. 이런 문서를 활용하여 AI 서비스를 구성하기 위해서는 S3 버킷에 텍스트 데이터를 수집해야 합니다. 문서들 중 Text 를 바로 활용할 수 없는 PDF 또는 스캔본과 같이 Image 로 된 문서들은 Amazon 의 Textract 를 통하여 Text를 추출하여 S3 버킷에 데이터를 수집합니다. Amazon Textract 은 스캔한 문서에서 텍스트, 필기 및 데이터를 자동으로 추출하여 단순한 광학 문자 인식 (OCR) 을 넘어 양식과 테이블에서 데이터를 식별하고 추출하는 기계 학습 서비스입니다.
2.2. NLP Pipeline
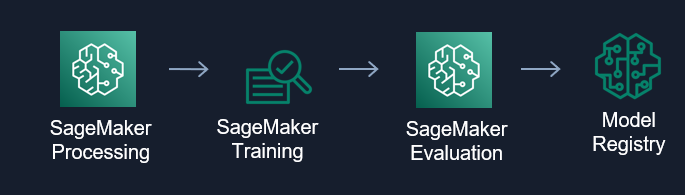
일반적으로 기계학습의 기본 Pipeline 은 데이터를 수집, 전 처리, 모델교육, 평가 및 프로덕션 배포의 단계로 나뉩니다. 이 작업은 복잡하고 시간이 오래 걸립니다. 모델을 훈련하기 위해 대량의 데이터를 관리하고, 훈련에 적합한 알고리즘을 선택하고, 훈련하는 도중에 컴퓨팅 용량을 관리하고, 모델을 프로덕션 환경에 배포 해야 합니다. NLP 에서도 마찬가지로 비슷한 과정을 거치며 Amazon SageMaker에서는 기계학습 모델을 훨씬 간편하게 구축 및 배포하고 훈련하기 위한 모든 기본 인프라를 쉽게 관리할 수 있습니다.
그럼 실제 예시를 들어 NLP Pipeline 의 구성을 설명하도록 하겠습니다. 아래 그림은 BERT 를 활용한 Text Classification 모델의 Pipeline 예시를 보여주고 있습니다.

① 모델을 만들기 위한 데이터를 S3 에서 가져오는 단계로 SageMaker 에서 S3에 접근할 수 있고, 특히 Athena 를 사용하여 S3 에 있는 데이터에 대해 바로 Query 기능을 수행하여 원하는 데이터를 가져올 수 있습니다.
② 데이터를 BERT 에 입력하여 Fine-tuning 을 진행하기위한 전처리를 진행합니다. Text 와 Label 데이터 분리 하고 Text의 tokenize 를 수행합니다. 이때 huggingface 와 같은 도구를 사용하면 간편하게 처리할 수 있습니다.
③ Fine-tuning 을 진행하기 위해 Train set 과 Test set 을 분리합니다.
④ Fine-tuning 을 위한 파라미터를 설정하고 실행합니다.
⑤ Fine-tuning 수행 완료 후 Accuracy 값을 확인하고 결과에 따라서 분기 처리를 할 수 있습니다.
⑥ Fine-tuning 수행 완료 후, AI 팀의 확인 결과 기준 (Accuracy) 에 부합한 개발 Model 을 Model Registry 에 등록합니다. 등록된 모델은 Trigger 를 통하여 SageMaker Endpoint 에 반영되어 실시간 추론을 수행하도록 합니다.
2.3. Hosting
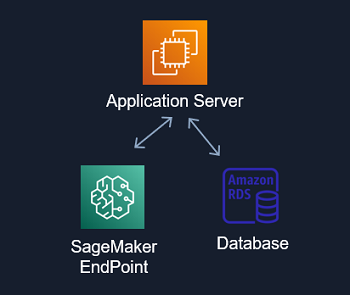
imtrial 의 AI 서비스에서 직접적인 사용자의 인터페이스를 담당하는 영역으로 사용자가 UI 를 통하여 NLP 관련 요청을 하게 되면 SageMaker Endpoint 의 배포된 모델의 실시간 추론 결과를 Application Server 를 통하여 사용자에게 전달하게 됩니다. 사용자 요청의 종류에 따라 SageMaker Endpoint 의 추론 결과와 Database 정보를 적절하게 조합하여 사용자에게 결과를 전달할 수 있습니다.
3. Conclusion
지금까지 imtrial AI 서비스의 NLP Pipeline 구성과 클라우드 기반의 데이터 수집부터 프로덕션 배포까지 빠르게 자동화 할 수 있는 구성을 확인하고 공유하였습니다.
imtrial 은 위의 내용을 기반으로 빠르게 AI 서비스를 구축하여 고객 여러분이 임상시험을 빠르게 진행할 수 있도록 프로세스를 가속화 할 것이니 많은 관심 부탁드립니다.
Clinical Platform Research Institute 에서는 위와같은 혁신적인 NLP AI 서비스를 함께 연구하고 개발하실 분을 모십니다. 많은 지원 부탁 드립니다.
*. AI Enginner Careers – https://www.imtrial.com/about-us/careers/?uid=4&mod=document&pageid=1
*. Apply for a job – 사람인 에서 “씨엔알리서치 임상기업부설연구소” 를 검색 해주세요.