1. Introduction
다른 산업과 마찬가지로 임상시험 분야도 다양한 소프트웨어가 만들어지고 있으며 이를 통해 대상자의 데이터를 수집하고, 임상시험용 의약품을 관리하고, 통계분석을 통하여 결과를 도출하는 등 다양한 역할에 사용하고 있습니다.
그러나 최근 팬데믹과 DCT (Decentralized Clinical Trials) 로의 디지털 기류 변화에 따라 환자 맞춤형 임상시험, 원격 임상시험 등으로 디지털 트랜스포메이션이 이루어지고 있습니다. 이에 따라 활용되는 데이터, 규정, 문서 등도 다양해지고 있습니다.
이런 기술적 패러다임의 변화에 대응하기 위해 가장 중요한 기술은 AI 중에서도 자연어 처리라는 분야입니다. 자연어 처리 (NLP : Natural Language Process) 는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고, 이를 구현하는 인공지능의 주요 연구분야의 하나입니다.
이런 내용을 기반으로 imtrial 에서 제공할 수 있는 서비스를 다음과 같이 구성하였습니다.
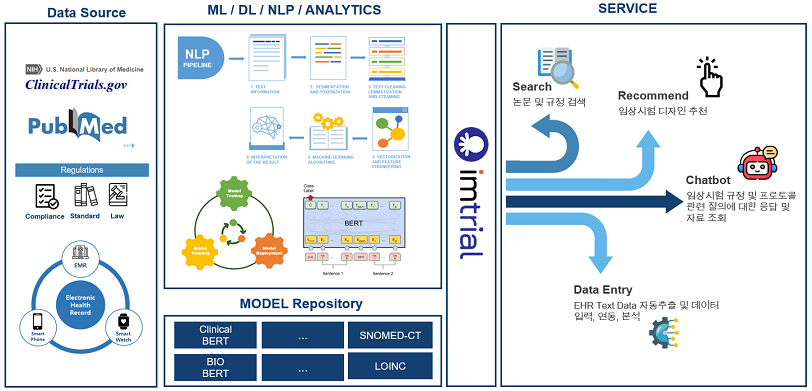
- Search
- 논문 및 규정과 같은 대량의 문서에서 키워드 기반 검색이 아닌 의미론적인 검색을 통하여 검색하고자 하는 내용에 바로 근접한 문서를 찾아주는 서비스
- Recommend
- ClinicalTrials.gov, PubMed 와 같은 텍스트 정보에서 임상시험 디자인 관련 내용을 추출 및 분류하여 진행하고자 하는 임상시험에 맞는 디자인을 추천해주는 서비스
- Chatbot
- 임상시험 규정 및 프로토콜의 내용을 기계가 이해하고 임상시험 진행 관련자 또는 임상시험 대상자의 질문에 답변할 수 있는 Q&A 챗봇 서비스
- Data Entry
- EHR 의 Text Data 와 같은 데이터에서 ETL 과 같은 시스템 개발없이 원하는 단어, 코드 및 값을 인지하여 자동으로 추출, 연동, 입력 분석해주는 서비스
2. Purpose
이번 Case Study 의 목적은 개요에서 소개한 imtrial 의 AI 서비스에 대해 기술을 구현하고 가능성을 검토하는 것으로 4개의 서비스 중 논문 및 규정 검색 관련하여 진행하였습니다.
ClinicalTrials.gov 에 등록되어 있는 40만 건에 가까운 임상시험 디자인 정보를 활용하여 임상시험에 대한 요약 문장을 입력하면 자연어 처리를 통해 문장을 이해하여 관련있는 임상시험 정보를 찾아주고 통계정보를 통하여 임상시험 디자인을 추천하도록 구현하였습니다.
3. Case Study Architecture
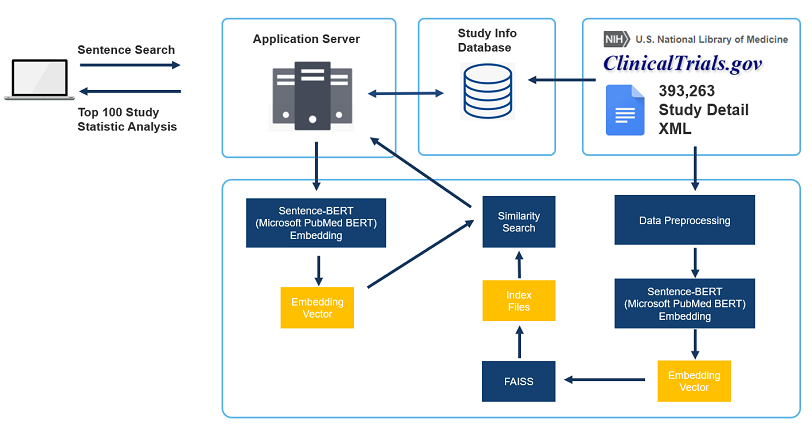
기본적인 컨셉은 사용자 인터페이스를 통해 찾고자 하는 임상시험의 요약 정보를 문장으로 기입하여 요청하면 ClinicalTrials.gov 에 등록되어 있는 393,263건의 임상시험 정보에서 유사도에 따라 100개 과제를 제시하고, 그 중에서 Study Type 과 Study Type 의 종류에 대한 정보를 이용하여 임상시험 디자인을 추천하는 것 입니다.
검색의 핵심은 문장의 유사도를 통하여 의미론적으로 가장 유사한 문장을 찾는 것인데 이를 위해 ClinicalTrials.gov 에 등록되어 있는 임상시험 정보에서 Study Summary 문장의 Embedding 을 통하여 Vector 로 변환하고 코사인 유사도를 기준으로 유사도를 측정하여 스터디를 검색하도록 하였습니다.
이 때, 코사인 유사도는 검색 문장의 Vector 와 비교하여 측정하게 되는데 ClinicalTrials.gov 전체 문장의 유사도를 각각 구하게 되면 시간이 오래 걸리기 때문에 FAISS 를 통하여 전체 Embedding Vector 를 Index 로 구성하여 검색 속도를 향상시켰습니다.
각각의 내용에 대해 다음 장에서 자세히 설명하겠습니다.
4. Key Point & Sample Code
Case Study 에 사용된 핵심 내용을 각각 정리하고 샘플 코드를 첨부하였습니다. 사용된 라이브러리 버전도 함께 표기하였습니다.
4.1. Data Pre-processing
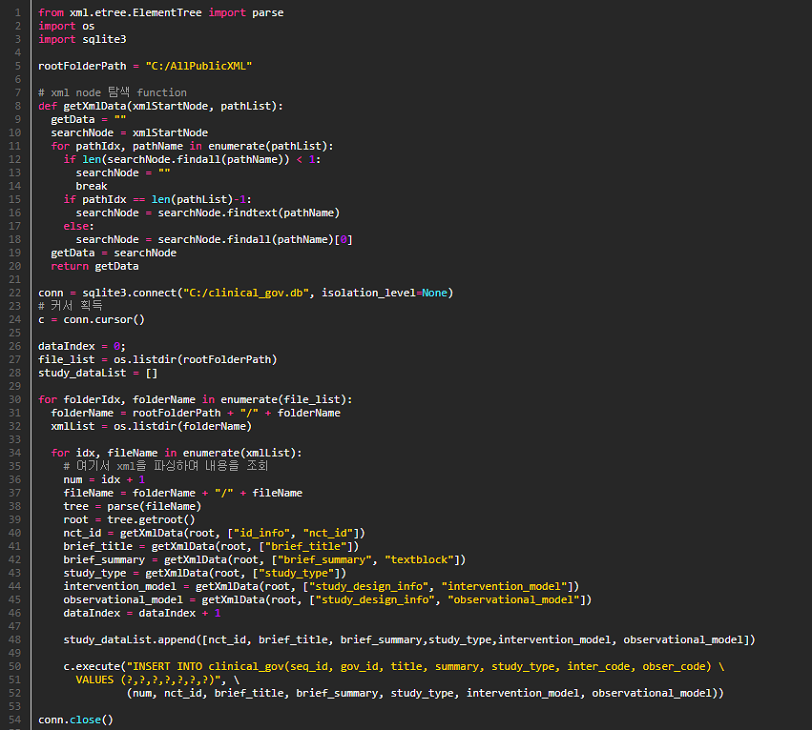
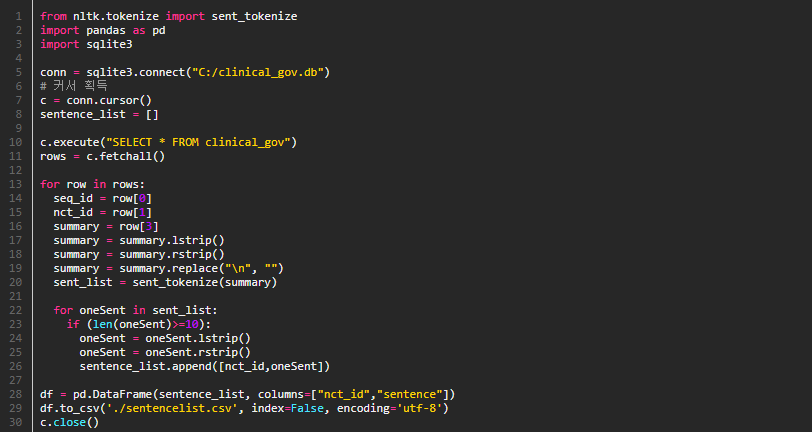
ClinicalTrials.gov 에서 데이터 전체를 다운로드하면 393,263개의 xml 파일이 있고 각각의 파일에서 nct_id, brief_title, brief_summary, study_type 을 추출하고 study_type 의 값에 따라 intervention_model, observation_model 을 추가로 추출하여 데이터베이스에 insert 합니다. 이때 brief_summary, study_type 및 study_type 에 따른 intervention_model, observation_model 값이 없는 경우 대상에서 제외합니다.
실제로 유사도 검색의 대상이 되는 brief_summary 데이터는 한 문장에서부터 수십개의 문장으로 이루어져 있는데 전체 데이터로 유사도를 검색하기 보다는 각 문장으로 분리하여 brief_summary 내용 중 일부 문장과 검색 문장과의 유사도를 기준으로 측정하는 것이 정확도가 높다고 판단하여 nltk 의 sent_tokenize 를 활용하여 각각의 문장으로 분리합니다.
분리된 문장의 결과를 보면 brief_summary 내의 1), 2) 와 같은 목록 번호도 표기가 되어 있는데 이 부분은 제거합니다.
# XML 정보 파싱하여 Database INSERT [Study 정보 및 통계정보를 위해 Database 입력]
# 문장을 Tokenize 하여 csv 파일로 생성
4.2. Sentence Embedding
문장의 의미 검색을 처리하는 일반적인 방법은 의미적으로 유사한 문장이 가깝도록 각 문장을 백터 공간에 매핑하는 것 입니다. 이것을 수치화하는 과정을 Sentence Embedding 이라고 합니다.
Sentence Embedding 방법에는 다양한 방법이 있는데 이 연구에서는 BERT 기반의 Sentence-BERT 를 사용합니다.
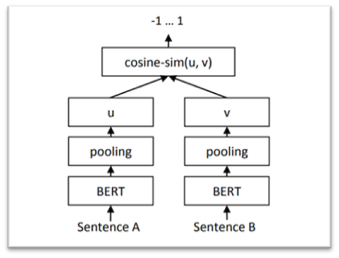
기존 BERT 네트워크 구조의 큰 단점은 독립적인 문장 임베딩이 계산되지 않아 BERT 에서 문장 Embedding 을 도출하기 어렵다는 것 입니다. 이것을 우회하기 위해 연구자들은 BERT 를 통해 단일 문장을 전달한 다음 출력을 평균하거나 첫 번째 토큰 (CLS 토큰) 의 출력을 사용하게 되는데 이것이 유용한 Embedding 이라는 평가가 없고 평균 GloVe Embedding 보다 종종 나쁜 임베딩을 생성합니다.
Sentence-BERT 는 기존 BERT 를 수정한 모델로 BERT 의 출력에 Pooling 연산을 추가하여 고정 크기의 문장 Embedding Vector 를 생성할 수 있으며 cosine-similarity 같은 유사도 측정을 사용하여 의미적으로 유사한 문장을 찾을 수 있습니다.
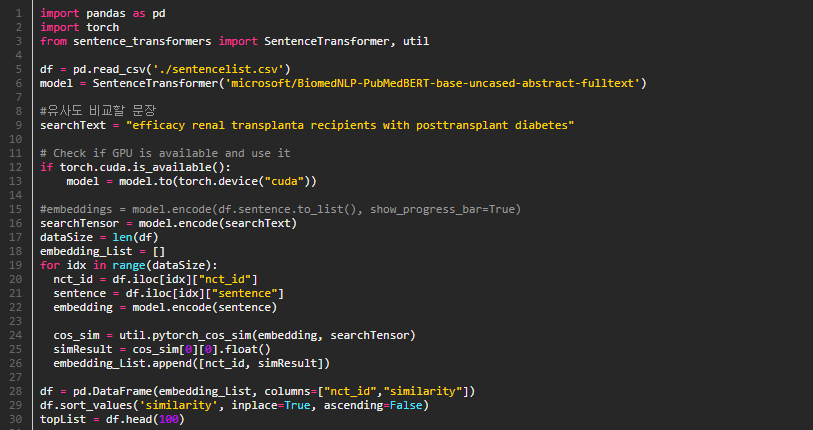
여기서 사용할 수 있는 Model 은 여러가지가 있는데 Biomedical 영역의 어휘를 이해할 수 있도록 Pubmed 의 abstract 와 fulltext 를 사전학습한 모델인 PubMedBERT 를 사용했습니다.
Model 을 통하여 Embedding Vector 가 생성되면 코사인 유사도를 통하여 문장의 유사도를 측정합니다. 코사인 유사도는 두 벡터의 크기가 아닌 각도의 값을 이용하여 방향의 유사도를 판단하게 되는데 두 벡터의 각도가 작을수록 벡터의 방향이 일치하게 되고 이것이 두 문장의 내용이 유사하다고 판단하는 기준이 됩니다.
4.3. FAISS
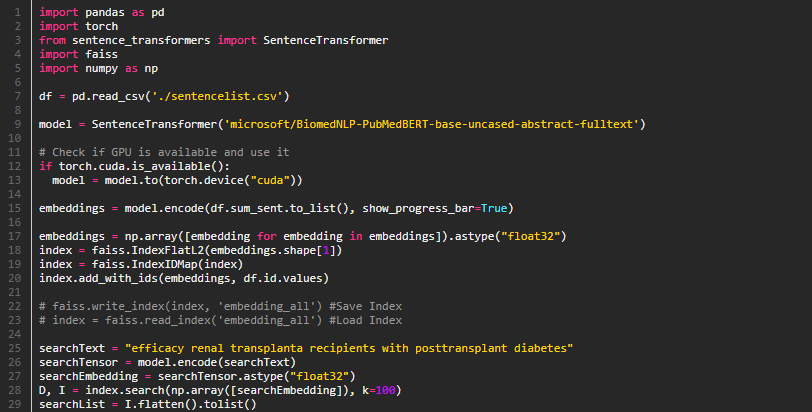
앞서 검색하는 문장과 ClinicalTrials.gov 전체 문장 각각의 코사인 유사도를 측정하여 유사도가 높은 기준으로 정렬하였는데 실제 수행시간이 20분 이상이 걸렸고 이 문제를 해결하기 위해 Index 검색을 적용하였습니다.
Facebook 에서 공개한 FAISS 라이브러리를 통하여 ClinicalTrials.gov 전체 문장의 Vector 를 Index File 로 생성하여 검색하도록 변경하였습니다.
5. Result
위 핵심 코드를 기반으로 브라우저에서 검색 및 결과를 확인할 수 있도록 Application 서버를 구축하고 UI 를 개발하였습니다.
임상시험에 관한 검색어 문장을 입력하고 검색 버튼을 클릭하면 유사한 Top 100 개의 스터디 목록을 제공합니다.
“investigate the effects and side effects of injection of botulinum toxin into the neck muscle for cervical headache”
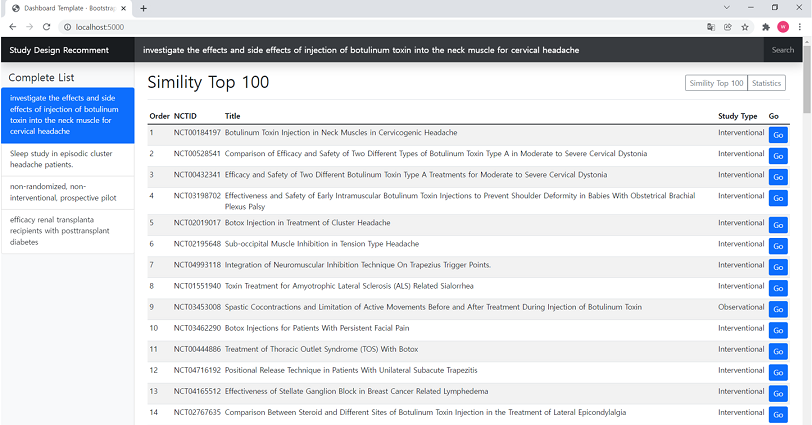
검색된 스터디 링크를 통해 ClinicalTrials.gov 로 해당 과제를 바로 연결합니다.
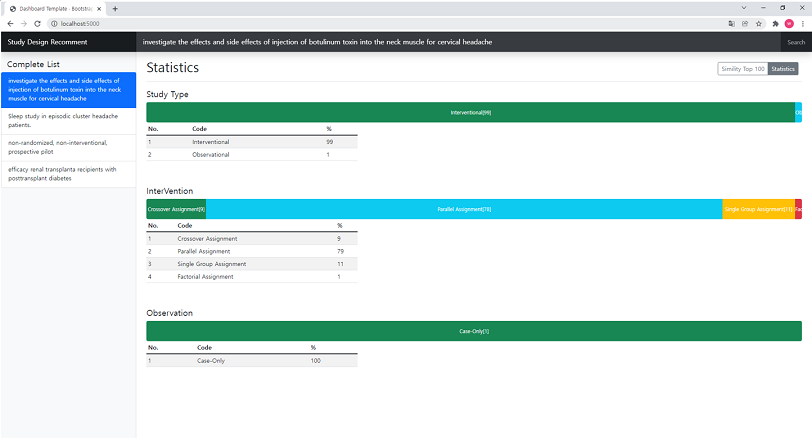
통계 정보를 조회하여 임상시험 디자인 정보를 확인합니다.
Study Type 은 “Interventional” 진행이 월등히 높고, “Interventional” 중에서도 Parallel Assignment 비율이 79% 로 가장 높습니다.
6. Conclusion
6.1. Case Study Evaluation
imtrial 의 Search 서비스 기술 관련하여 Case Study 를 구현하고 확인해 봤습니다.
ClinicalTrials.gov 393,263개의 전체 데이터에서 Summary 정보 및 Study Design 코드 정보가 있는 364,805개의 스터디를 검색하였으며, 실제로 검색된 Top 100 을 순위별로 확인하였을 때 상위 순위일수록 경추성 두통과 보툴리눔 독소와 직접 관련된 임상시험 목록을 보여주는 것이 확인되어 검색이 잘 동작하느 것을 확인할 수 있었습니다.
6.2. Performance
393,263개의 스터디 Summary 정보에서 분리된 실제 검색 대상이 되는 개별 문장은 1,387,665개로 전체 index 검색에 1.3초가 소요되어 검색 성능이 좋은 것을 확인할 수 있었습니다. 테스트 환경은 노트북에서 수행하였으며 실제 서버로 구성할 경우 더 빠르게 검색될 것으로 예상됩니다.
6.3. improvement & Next Step
이번 Case Study 에서는 스터디 전체 데이터 중 Brief Summary 만 기준으로 검색하였고 사용한 모델이 ClinicalTrials 를 훈련한 모델이 아니기 때문에 이 부분을 개선하면 더욱 좋은 검색 기능을 제공할 것으로 예상합니다.
그리고 다음에는 ClinicalTrials.gov 전체 텍스트를 기준으로 직접 사전훈련을 진행하고 선정제외 기준, Primary Outcome 등 다른 데이터도 함께 활용하여 더욱 정확한 검색 기능이 될 수 있도록 개선할 것 입니다.
Clinical Platform Research Institute 에서는 위와같은 혁신적인 NLP AI 서비스를 함께 연구하고 개발하실 분을 모십니다. 많은 지원 부탁 드립니다.
*. AI Enginner Careers – https://www.imtrial.com/about-us/careers/?uid=4&mod=document&pageid=1
*. Apply for a job – 사람인 에서 “씨엔알리서치 임상기업부설연구소” 를 검색 해주세요.